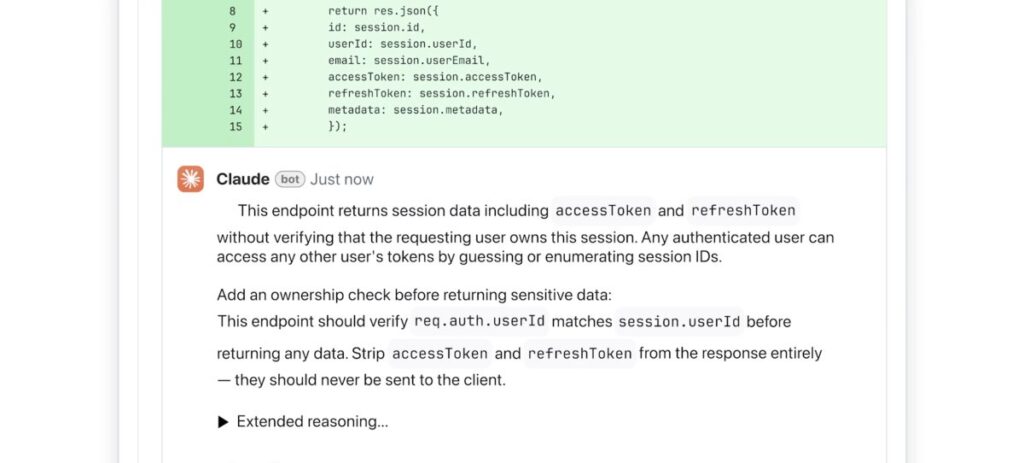
A Anthropic anunciou nesta terça-feira, 24 de março de 2026, o Auto Mode, novo recurso do Claude Code que permite à inteligência artificial decidir, por conta própria, quais comandos pode executar de forma segura. A função está em research preview – fase de testes que antecede o lançamento definitivo – e busca equilibrar autonomia e controle no desenvolvimento assistido por IA.
O sistema analisa cada ação antes da execução para detectar comportamentos não solicitados pelo usuário ou tentativas de prompt injection, em que instruções maliciosas ficam ocultas no conteúdo processado. Caso a verificação considere o comando seguro, ele é executado automaticamente; se houver risco, a operação é bloqueada.
O Auto Mode expande o comando já existente dangerously-skip-permissions, que entregava todas as decisões ao modelo, mas agora acrescenta uma camada de proteção interna. Segundo a Anthropic, a novidade coloca na própria IA a responsabilidade de decidir quando solicitar ou não autorização, etapa que antes exigia intervenção humana constante.
Questionada, a empresa ainda não detalhou os critérios usados para classificar ações como seguras ou perigosas, ponto que deve ser esclarecido antes de uma adoção mais ampla por parte dos desenvolvedores.
O lançamento sucede outras soluções recentes da companhia, como o Claude Code Review, que revisa códigos para encontrar erros antes de serem integrados ao repositório, e o Dispatch for Cowork, que delega tarefas a agentes de IA.

Imagem: Internet
De acordo com a Anthropic, o Auto Mode será disponibilizado “nos próximos dias” para clientes Enterprise e usuários de API. Inicialmente, funcionará apenas com os modelos Claude Sonnet 4.6 e Claude Opus 4.6. A recomendação é utilizá-lo em ambientes isolados (sandbox), separados dos sistemas de produção, para limitar possíveis impactos caso algo saia do previsto.
Com informações de TechCrunch