Pesquisadores do Instituto de Tecnologia de Massachusetts (MIT) desenvolveram um método que permite a robôs gerar mapas tridimensionais de ambientes complexos em poucos segundos, utilizando apenas imagens captadas por suas câmeras.
Apresentada em 6 de novembro de 2025, a abordagem combina modelos recentes de visão por inteligência artificial com conceitos clássicos de visão computacional, eliminando a necessidade de câmeras calibradas ou ajustes manuais complexos.
Como funciona
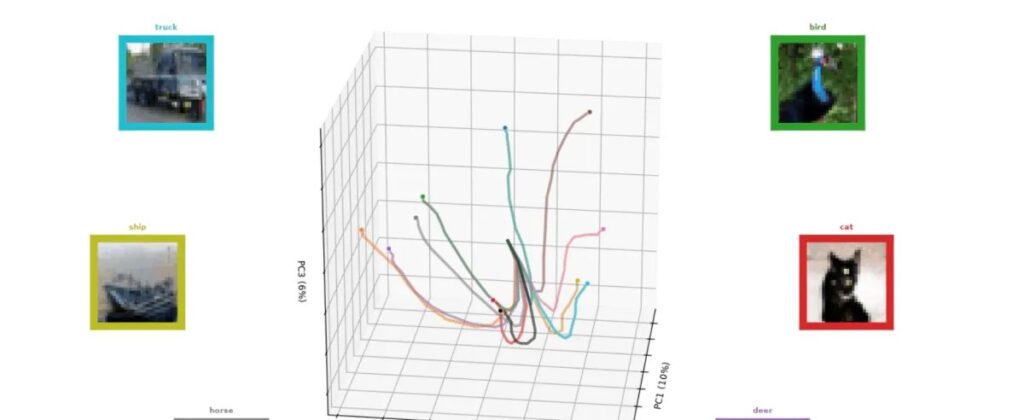
O sistema cria pequenos submaps — representações parciais do cenário — e os alinha progressivamente até formar um mapa 3D completo enquanto estima, em tempo real, a posição do robô. Para corrigir deformações introduzidas pelo aprendizado de máquina, os cientistas aplicam transformações matemáticas que padronizam cada submap antes da junção final.

Resultados
Em testes, a técnica reconstruiu ambientes como corredores de escritório e até o interior da Capela do MIT com erro médio inferior a 5 cm, processando apenas vídeos curtos gravados por celular. O desempenho superou métodos atuais em velocidade e precisão, sem exigir sensores especiais.



Aplicações
Além de operações de busca e resgate em minas ou áreas colapsadas, a solução pode beneficiar óculos de realidade estendida e robôs industriais encarregados de localizar produtos em armazéns.

Imagem: Internet
Equipe e próxima etapa
O trabalho foi liderado pelo doutorando Dominic Maggio, com participação do pós-doutor Hyungtae Lim e do professor Luca Carlone, do Departamento de Aeronáutica e Astronáutica do MIT. O artigo “VGGT-SLAM: Dense RGB SLAM Optimized on the SL(4) Manifold” será apresentado na Conference on Neural Information Processing Systems (NeurIPS). Os pesquisadores planejam ampliar a robustez do sistema para cenários ainda mais desafiadores e implementá-lo em robôs reais.
Com informações de Nanowerk